F: 함수
함수의 이름은 전달인자(argument)들의 요구사항을 드러내고, 인자들과 호출 결과간의 관계를 명확히 기술해야 한다. 세부 구현은 명세가 아니다. 함수가 어떻게 작동하는지만큼이나 무엇을 하는지도 생각해 보라. 함수는 대부분 인터페이스에서 가장 중요한 부분이므로, 인터페이스 규칙도 살펴 보라.
함수는 시스템이 모순없는(consistent) 어떤 상태에서 다음 상태로 이행하도록 하는 동작(action)이나 계산(computation)을 명세하는(specify) 것이다. 이는 프로그램의 기본 재료(building block)이다.
역주: * Parameter: 매개변수 * Argument: 전달인자
함수 규칙 요약:
함수 정의 규칙:
- F.1: 의미있는 동작들을 "묶어서" 함수로 만들고 신중하게 이름을 지어라
- F.2: 함수는 하나의 논리적 동작만 수행해야 한다
- F.3: 함수는 간결하고 단순하게 유지하라
- F.4: 함수가 컴파일 시간에 평가되어야 한다면
constexpr로 선언하라 - F.5: 함수가 매우 짧고 수행시간이 중요하다면
inline으로 선언하라 - F.6: 함수가 예외를 던지지 않는다면
noexcept로 선언하라 - F.7: 보편성을 고려한다면, 스마트 포인터 대신에
T*나T&타입의 인자를 사용하라 - F.8: 순수 함수를 선호하라
- F.9: 사용되지 않는 인자는 이름이 없어야 한다
매개변수 전달 표현(parameter passing expression) 규칙:
- F.15: 정보를 전달 할 때 단순하고 관습적인 방법을 선호하라
- F.16: "입력(in)" 매개변수는 복사 비용이 적게 드는 타입의 경우 값으로 전달하고, 그 외에는 상수 참조형으로 전달하라
- F.17: "입출력(in-out)" 매개변수는 비상수 참조형으로 전달하라
- F.18: "넘겨주는(will-move-from)" 매개변수는
X&&타입과std::move로 전달하라 - F.19: "전달(forward)" 매개변수는
TP&&타입과std::forward로만 전달하라 - F.20: "출력(out)"에는 매개변수보다는 값을 반환하는 방법을 선호하라
- F.21: "출력"값 여러 개를 반환할 때는 튜플이나 구조체를 선호하라
매개변수 전달 의미구조(parameter passing semantic) 규칙:
- F.22: T* 혹은 owner
- F.23: "null"이 허용되지 않는다면
not_null<T>를 사용해 표시하라 - F.24: 범위를 지정할 때는
span<T>혹은span_p<T>를 사용하라 - F.25: C 스타일 문자열에는
zstring혹은not_null<zstring>을 사용하라 - F.26: 포인터가 필요한 곳에 소유권을 전달할 때는
unique_ptr<T>를 사용하라 - F.27: 소유권을 공유할 때는
shared_ptr<T>를 사용하라 - F.60: "인자가 없을 경우"를 허용한다면
T&보다는T*를 선호하라
- F.42: 위치를 나타내는 경우에만
T*를 반환하라 - F.43: 절대로 (직접적이든 간접적이든) 지역 개체의 포인터나 참조를 반환하지 말아라
- F.44: 복사를 권장하지 않거나 "개체를 항상 반환"한다면
T&를 반환하라 - F.45:
T&&를 반환하지 말아라 - F.46:
main()는int를 반환해야 한다 - F.47: 대입 연산자는
T&를 반환하라 - F.48:
return std::move(local)은 사용하지 말아라
기타 함수 규칙:
- F.50: 함수를 쓸 수 없을 때는 람다를 사용하라(지역 변수를 캡쳐하거나 지역 함수를 작성할 때)
- F.51: 선택할 수 있다면, 중복 정의보다는 기본 전달인자를 선호하라
- F.52: 지역적으로 사용된다면 람다의 참조 캡쳐를 선호하라
- F.53: 지역적으로 사용되지 않는다면 참조 캡쳐를 피하라
- F.54:
this를 캡쳐할 때는, 모든 변수를 명시적으로 캡쳐하라(기본 캡쳐를 사용하지 않는다) - F.55:
va_arg전달인자를 사용하지 말아라
함수는 람다와 함수개체와 강한 연관성을 가지고 있다.
See also
C.lambdas: Function objects and lambdas
F.def: 함수 정의(definition)
함수 정의는 함수의 본문을 구현하면서 선언하는 것이다.
F.1: 의미있는 동작들을 "묶어서" 함수로 만들고 신중하게 이름을 지어라
Reason
공통된 코드를 묶어 내면 가독성이 높아지고, 재사용하기 좋아지고, 복잡한 코드에서 오류가 나타나는 범위를 제한한다. 잘 명세된 행동이라면 이를 주변 코드로부터 분리시키고 이름을 부여하라.
Example, don't
void read_and_print(istream& is) // read and print an int
{
int x;
if (is >> x)
cout << "the int is " << x << '\n';
else
cerr << "no int on input\n";
}
read_and_print 함수의 거의 모든 부분이 잘못되었다. 이 함수는 어떤 값을 읽고, ostream에 쓰거나 오류 메시지를 쓰는데, 오로지 int만을 다룬다.
재사용 가능한 코드가 없고, 논리적으로 별개인 동작이 뒤섞여 있으며, 지역변수는 논리상 소용이 없어진 뒤에도 남아 있다.
작은 예에서라면 괜찮아 보이지만, 이 입력동작, 출력동작, 그리고 오류처리가 더 복잡했더라면 뒤엉킨 코드 덩어리가 이해하기 어려워졌을 것이다.
Note
만약 한 곳 이상에서 사용 될 중요한 람다 함수를 작성한다면 (비지역)변수에 할당하고 이름을 부여하라.
Example
sort(a, b, [](T x, T y) { return x.rank() < y.rank() && x.value() < y.value(); });
람다에 이름을 부여하면 표현식을 여러 개의 논리적 부분으로 나눌 수 있고, 그 람다가 하는 일을 짐작케 할 수 있다.
auto lessT = [](T x, T y) { return x.rank() < y.rank() && x.value() < y.value(); };
sort(a, b, lessT);
find_if(a, b, lessT);
코드가 짧다고 성능이나 유지보수성이 항상 좋지만은 않다.
Exception
반복문(loop bodies)은, 람다인 경우도 마찬가지인데, 이름을 지을 필요가 거의 없다. 하지만 수십 줄이나 수십 쪽에 걸친 거대한 반복문은 문제가 될 수 있다. 함수를 간결하게 유지하라 규칙에는 "반복문을 짧게 유지하라"라는 뜻도 있다. 이와 유사하게, 콜백 인자로 사용되는 람다는 때로 한눈에 알아볼 수 없지만, 재사용될 가망이 거의 없다. (따라서 이름을 지어 줄 필요가 거의 없다.)
Enforcement
- 함수를 간결하게 유지하라를 참고하라
- 동일하거나 매우 비슷한 람다가 여러 곳에서 사용되면 지적하라
F.2: 함수는 하나의 논리적 동작만 수행해야 한다
Reason
하나의 작업만 수행하는 함수는 이해하기 쉽고, 테스트하기 쉽고, 재사용하기 쉽다.
Example
다음을 고려해 보자:
void read_and_print() // bad
{
int x;
cin >> x;
// check for errors
cout << x << "\n";
}
이는 특정한 입력에 매여 있는 통짜로 된 함수로, 다른 쓰임새를 찾을 수 없다. 대신에 함수를 적절한 논리적 부분으로 쪼개고 cin, cout 등은 매개변수로 사용하라:
int read(istream& is) // better
{
int x;
is >> x;
// check for errors
return x;
}
void print(ostream& os, int x)
{
os << x << "\n";
}
필요하다면 두 함수를 결합하면 된다:
void read_and_print()
{
auto x = read(cin);
print(cout, x);
}
또한 필요하다면 read()와 print()에서 사용하는 데이터 타입, 입력 메커니즘, 오류에 대한 응답 등을 템플릿화 할 수 있다.
예를 들어:
auto read = [](auto& input, auto& value) // better
{
input >> value;
// check for errors
};
auto print(auto& output, const auto& value)
{
output << value << "\n";
}
Enforcement
- 출력 매개변수가 2개 이상인 함수를 의심하라. 대신 반환값을 사용하라. 여러 반환값을 저장 할 수 있는
tuple을 사용해도 좋다. - 편집기 화면에 다 나오지 않을 만큼 큰 함수를 의심하라. 이런 함수는 세부 동작을 갖는 더 작은 함수들로 (이름을 잘 지어서) 나누도록 한다.
- 7개 이상의 매개변수를 갖는 함수를 의심하라.
F.3: 함수는 간결하고 단순하게 유지하라
Reason
거대한 함수는 읽기 어려울 뿐더러, 복잡한 코드를 포함하거나, 필요한 유효범위 이상으로 존재하는 변수가 있을 가능성이 더 높다. 제어 구조가 복잡한 함수는 길이가 길기 마련이고, 논리 오류가 숨어있을 공산이 크다.
Example
다음의 예를 보라:
double simple_func(double val, int flag1, int flag2)
// simple_func: takes a value and calculates the expected ASIC output,
// given the two mode flags.
{
double intermediate;
if (flag1 > 0) {
intermediate = func1(val);
if (flag2 % 2)
intermediate = sqrt(intermediate);
}
else if (flag1 == -1) {
intermediate = func1(-val);
if (flag2 % 2)
intermediate = sqrt(-intermediate);
flag1 = -flag1;
}
if (abs(flag2) > 10) {
intermediate = func2(intermediate);
}
switch (flag2 / 10) {
case 1: if (flag1 == -1) return finalize(intermediate, 1.171);
break;
case 2: return finalize(intermediate, 13.1);
default: break;
}
return finalize(intermediate, 0.);
}
이 함수는 너무 복잡하다. 가능한 모든 경우를 올바르게 다루었는지 어떻게 알겠는가? 게다가, 이 예는 다른 규칙도 어기고 있다.
이렇게 바꿔쓸 수 있다:
double func1_muon(double val, int flag)
{
// ???
}
double func1_tau(double val, int flag1, int flag2)
{
// ???
}
double simple_func(double val, int flag1, int flag2)
// simple_func: takes a value and calculates the expected ASIC output,
// given the two mode flags.
{
if (flag1 > 0)
return func1_muon(val, flag2);
if (flag1 == -1)
// handled by func1_tau: flag1 = -flag1;
return func1_tau(-val, flag1, flag2);
return 0.;
}
Note
"한 화면에 맞추기"는 "너무 크게 하지 않기"에 대한 좋은 실용적인 규칙이다. 한줄에서 다섯줄 사이의 함수는 정상으로 간주한다.
Note
긴 함수는 응집성있고 의미있는 이름을 가진 작은 함수로 나누어야 한다. 작고 간결한 함수는 함수 호출 비용이 중요한 곳에서 inline처리될 수 있다.
Enforcement
- "한 화면에 맞지 않는" 함수는 지적한다.
화면은 어느정도 크기로 할 것인가? 한 줄에 140자, 60줄 화면을 사용해보라; 이는 대략 책의 한 페이지에 맞는 최대 크기이다. - 너무 복잡한 함수는 지적한다.
너무 복잡한은 어느정도를 의미하는가? 순환 복잡도(cyclomatic complexity)를 쓸 수도 있다. "10개의 논리적 경로"를 사용해보라. 단순한 switch는 하나로 세어도 좋다.
F.4: 함수가 컴파일 시간에 평가되어야 한다면 constexpr로 선언하라
Reason
constexpr는 컴파일 시간에 평가하라고 컴파일러에게 지시하는데 사용된다.
Example
유명한 팩토리얼:
constexpr int fac(int n)
{
constexpr int max_exp = 17; // constexpr enables max_exp to be used in Expects
Expects(0 <= n && n < max_exp); // prevent silliness and overflow
int x = 1;
for (int i = 2; i <= n; ++i) x *= i;
return x;
}
C++14 에서는 이와 같이 작성할 수 있다. C++ 11 환경이라면, fac()를 재귀를 사용해 작성해야 한다.
Note
constexpr은 컴파일 타임 평가를 보장하지 않는다; 단지 프로그래머가 요구하거나 컴파일러가 최적화를 하기로 결정했을 때 상수 표현 인자에 대해서 컴파일 타임에 평가 될 수 있다는 것만을 보장 할 뿐이다.
constexpr int min(int x, int y) { return x < y ? x : y; }
void test(int v)
{
int m1 = min(-1, 2); // probably compile-time evaluation
constexpr int m2 = min(-1, 2); // compile-time evaluation
int m3 = min(-1, v); // run-time evaluation
constexpr int m4 = min(-1, v); // error: cannot evaluate at compile time
}
Note
모든 함수를 constexpr로 작성하지는 마라. 대부분의 계산은 실행시간에 최적으로 수행된다.
Note
어떤 API가 높은 수준의 실행시간 설정(configuration) 혹은 비즈니스 로직에 의존한다면 constexpr로 작성해선 안된다.
그와 같은 경우는 컴파일러에 의해 평가될 수 없으며, 그 API에 의존하는 constexpr 함수들은 재구성(refactored)되거나 constexpr를 포기(drop)하게 될 것이다.
Enforcement
불가능하며 불필요하다.
컴파일러가 상수가 필요한 곳에 constexpr가 아닌 함수들이 사용되면 오류로 처리할 것이다.
F.5: 함수가 매우 짧고 수행시간이 중요하다면 inline으로 선언하라
Reason
일부 최적화기(optimizer)는 별도로 힌트를 받지 않아도 함수 인라인화를 잘 하지만, 그에 의존해서는 안된다.
측정하라! 지난 40년간 우리는 컴파일러가 아무런 힌트가 없어도 사람보다 더 인라인화를 잘 할거라고 약속해 왔다.
그리고 그 약속은 아직 지켜지지 않았다. inline을 명시하는 것은 컴파일러가 더 나은 코드를 생성하도록 권장하는 것이다.
Example
inline string cat(const string& s, const string& s2) { return s + s2; }
Exception
함수가 변하지 않을 것이라고 확신하지 않는 한, inline을 안정된 인터페이스 함수에 사용해선 안된다.
인라인 함수는 ABI의 일부이다.
Note
constexpr은 inline을 내포하고 있다.
Note
클래스 내에 정의된 멤버 함수들은 기본적으로 inline이 적용된다.
Exception
템플릿 함수(템플릿 멤버 함수 포함)들은 보통 헤더 파일에 정의되기 때문에 인라인 함수에 해당한다.
Enforcement
inline함수가 3 문장보다 길고 (클래스의 멤버 함수처럼) 다른 곳에 선언되었다면 지적한다.
F.6: 함수가 예외를 던지지 않는다면 noexcept로 선언하라
Reason
예외를 던지지 않는다면 프로그램이 오류에 대처하리라 생각할 수 없고, 이는 최대한 빠르게 종료되어야 마땅하다. 함수를 noexcept로 선언하면 대안적인 실행경로가 줄어듦으로 최적화가 쉬워진다. 오류가 난 뒤 종료할 때까지 시간도 짧아진다.
Example
온전히 C언어로 구현이 되었거나 예외를 지원하지 않는 모든 함수에 noexcept를 추가하라. C++ 표준 라이브러리는 C 표준 라이브러리에 대해서 암시적으로 그렇게하고 있다.
Note
constexpr 함수가 실행시간에 평가된다면 예외가 발생할 수 있기 때문에, noexcept를 명시해야 할 수 있다
Example
예외를 던질 수 있는 함수에서 noexcept를 사용하는 것도 가능하다:
vector<string> collect(istream& is) noexcept
{
vector<string> res;
for (string s; is >> s;)
res.push_back(s);
return res;
}
collect() 함수가 메모리를 모두 사용해 버리면 프로그램은 비정상적으로 종료하게 된다. 프로그램이 메모리 고갈 상태를 해결할 수 없다면, 이는 당연한 결과라고 할 수 있다;
terminate() 함수에서 적합한 오류 기록(error log)을 생성할 수 있다. (하지만 메모리 부족 상황에서는 제대로 할 수 있는 일이 거의 없다)
Note
어떤 함수에 noexcept를 붙일지 말지 결정할 때는 코드가 실행되는 환경을 알고 있어야 한다. 특히나 예외를 던지는 것이 메모리 할당 문제를 일으킬 수 있다. 표준 라이브러리나 sort같은 여타 유틸리티 코드처럼, 완전히 일반적으로 쓰일 것을 염두에 둔 코드는 bad_alloc 예외가 제대로 처리되는 환경을 지원할 필요가 있다.
하지만 대부분의 프로그램 및 실행환경은 메모리 할당 실패를 제대로 처리하지 못하는데, 그럴 때는 프로그램을 종료시켜 버리는 것이 가장 깔끔하고 간단한 처리방법이다.
당신이 짠 응용프로그램 코드가 메모리 할당 실패에 대처하지 못하리라는 점을 안다면, 메모리를 할당하는 함수에도 noexcept를 덧붙이는 것이 적절할 수도 있다.
다르게 생각하면:
대부분의 프로그램에서는 함수들은 보통 예외를 던진다 (함수 안에서 new를 사용하거나 예외를 던지는 방식으로 실패를 알리는 함수/라이브러리를 사용하는 경우). 따라서 발생가능한 예외가 처리될 수 있는지 고민하지 않고 noexcept를 남발해서는 안된다.
noexcept는 빈번히 호출되는 저수준 함수들에 유용하다 (또한 정확하다).
Note
소멸자, swap 함수, move 연산 그리고 기본 생성자에서는 절대로 예외를 던지면 안된다.
Enforcement
- 예외를 던질 수 없는데도
noexcept가 없는 함수가 있다면 지적한다 - 예외를 던지는
swap, move 연산자, 소멸자 그리고 기본 생성자가 있다면 지적한다
F.7: 보편성을 고려한다면, 스마트 포인터 대신에 T*나 T& 타입의 인자를 사용하라
Reason
스마트 포인터를 인자로 사용하면 소유권이 이전되거나 공유된다. 이는 의도적인 경우에만 사용되어야 한다. (R.30 참고).
스마트 포인터를 인자로 사용하면 함수 호출 시 스마트 포인터를 사용해야한다는 제약이 생긴다.
공유 스마트 포인터를 인자로 사용하는 것은 (예, std::shared_ptr) 런타임시 추가 비용을 발생시킨다.
Example
// accepts any int*
void f(int*);
// can only accept ints for which you want to transfer ownership
void g(unique_ptr<int>);
// can only accept ints for which you are willing to share ownership
void g(shared_ptr<int>);
// doesn't change ownership, but requires a particular ownership of the caller
void h(const unique_ptr<int>&);
// accepts any int
void h(int&);
Example, bad
// callee
void f(shared_ptr<widget>& w)
{
// ...
use(*w); // only use of w -- the lifetime is not used at all
// ...
};
R.30에서 관련 내용을 기술하고 있다.
Note
허상 포인터(dangling pointer)는 정적으로 잡아낼 수 있다. 때문에 허상 포인터로 인한 자원 관리에 의존할 필요는 없다.
See also
Enforcement
소유권 의미구조를 사용하지 않는데 스마트 포인터 타입을 인자로 사용한다면 지적한다 (또는 operator->나 operator*를 중복정의한 타입). 이런 경우는
- 복사 가능하지만 복사/이동이 발생하지 않는다 혹은 이동 가능하지만 이동하지 않는다
- 값을 변경하지 않거나 변경하지 않는 다른 함수로 전달한다
F.8: 순수 함수를 선호하라
Reason
순수 함수는 좀 더 파악하기 쉽다. 최적화하기 쉽고(병렬화를 포함한다), 메모이제이션하기 쉽다.
Example
template<class T>
auto square(T t) { return t * t; }
Enforcement
불가능하다.
F.9: 사용되지 않는 인자는 이름이 없어야 한다
Reason
가독성. "사용되지 않는 인자" 경고가 발생하지 않게 한다.
Example
X* find(map<Blob>& m, const string& s, Hint); // once upon a time, a hint was used
Note
이 문제를 다루기 위해 1980년대 초에 이름 없는 매개변수를 허용하게 되었다
Enforcement
이름이 있지만 사용되지 않는 매개변수를 지적한다.
F.call: 매개변수 전달(Parameter passing)
함수에 인자를 전달하고 반환값을 받는데는 다양한 방법이 있다.
F.15: 정보를 전달 할 때 단순하고 관습적인 방법을 선호하라
Reason
"별나면서 교묘한" 기법은 깜짝놀랄만한 버그를 만들어내거나, 다른 프로그래머가 코드를 이해하는데 어렵게 만든다. 정말로 일반적인 기법을 넘어서는 방법으로 최적화를 해야 한다면 꼭 필요한 개선사항이라는것을 확신할 수 있어야하고, 이식성이 없을 수 있기 때문에 문서나 주석을 남겨야 한다.
아래의 표는 핵심 가이드라인의 조언(F.16-21)을 요약한 것이다.
매개변수 전달(Normal):
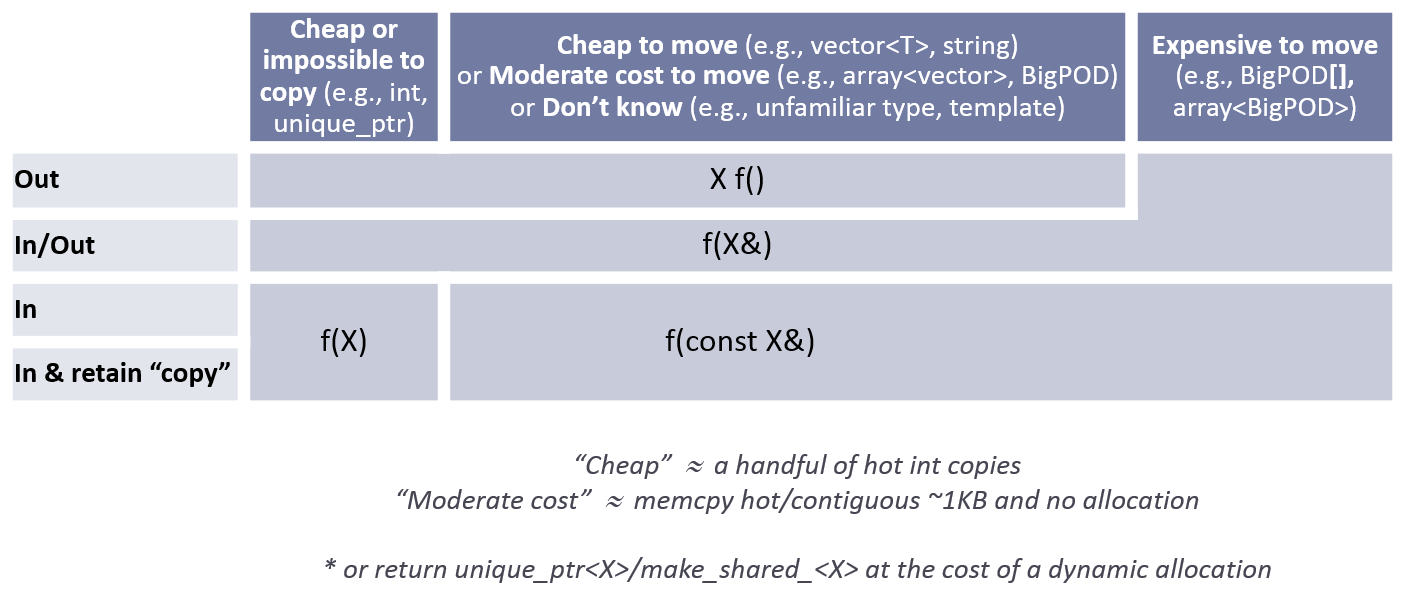
매개변수 전달(Advanced):

필요한 경우에만 고급 기술을 사용하고, 주석으로 문서화하라.
F.16: "입력(in)" 매개변수는 복사 비용이 적게 드는 타입의 경우 값으로 전달하고, 그 외에는 상수 참조형으로 전달하라
Reason
두 경우 모두 호출자가 전달인자를 변경하지 않는다는 것을 알 수 있다. 또한 r-value 초기화를 허용한다.
"큰 비용 없이 복사" 한다는 것은 실행기(machine)의 구조(architecture)에 따라 다르다. 하지만 보통 2,3개의 워드(double, 포인터, 참조)를 값으로 전달할때 최적이다.
비용이 적다면, 단순성과 안전성에서 복사보다 나은 방법은 없다. 또한 작은 개체(2,3개 워드까지)에 대해선 참조보다 복사가 빠른데 함수에서 간접(in-direct)접근없이 사용할 수 있기 때문이다.
Example
void f1(const string& s); // OK: pass by reference to const; always cheap
void f2(string s); // bad: potentially expensive
void f3(int x); // OK: Unbeatable
void f4(const int& x); // bad: overhead on access in f4()
"입력 전용" 매개변수로 전달된 r-value를 최적화하고자 한다면:
- 함수에서 무조건적으로 전달인자를 이동(move)받는다면,
&&를 사용하라. F.18 참고 - 인자의 복사본을 사용한다면, 매개변수에 (l-value인 경우)
const&를 사용하는 함수와 (r-value인 경우)&&를 받아 필요한 영역에std::move하는 함수를 중복 정의하라. 원래 이는 "will-move-from"을 중복정의한 것이다. F.18 참고 - "입력 + 복사"가 여럿 발생하는 특별한 경우에는, "perfect forwarding" 사용을 고려하라. F.19 참고
Example
int multiply(int, int); // just input ints, pass by value
// suffix is input-only but not as cheap as an int, pass by const&
string& concatenate(string&, const string& suffix);
void sink(unique_ptr<widget>); // input only, and moves ownership of the widget
아래와 같은 "난해한 기술"은 지양하라:
- "효율적이라서" 인자를
T&&로 전달한다.&&로 전달함으로써 발생하는 성능 향상에 대한 루머는 잘못되었고 깨지기 쉽다(속단하지 말고 F.18와 F.19를 참고하라) - 대입에서
const T&를 반환하거나 비슷한 연산을 수행한다 (F.47 참고)
Example
Matrix가 이동 연산을 지원한다고 가정하자(아마도 원소들을 std::vector에 보관하고 있다):
Matrix operator+(const Matrix& a, const Matrix& b)
{
Matrix res;
// ... fill res with the sum ...
return res;
}
Matrix x = m1 + m2; // move constructor
y = m3 + m3; // move assignment
Notes
반환 값 최적화는 대입에 대해서는 동작하지 않지만, 이동 대입의 경우에는 적용된다.
참조는 언어 규칙에 의해 유효한 개체를 가리킨다고 가정하기 때문에, null 참조는 발생하지 않는다.
optional 값에 대해 알고 있다면, 포인터를 사용하거나, std::optional 혹은 "값이 없음"을 의미하는 특별한 값을 사용하라.
Enforcement
- (쉬움) (기본 사항) 인자의 크기가
4 * sizeof(int)보다 크면 경고한다.const참조를 전달하도록 제안한다 - (쉬움) (기본 사항)
const참조로 전달되는 인자의 크기가3 * sizeof(int)보다 작다면 경고한다. 값 전달을 대신 사용하도록 제안한다 - (쉬움) (기본 사항)
const참조 매개변수가move되면 경고한다
F.17: "입출력(in-out)" 매개변수는 비상수 참조형으로 전달하라
Reason
호출자에게 값이 변경될 수 있다는 점을 분명히 할 수 있다.
Example
void update(Record& r); // assume that update writes to r
Note
T& 인자는 정보를 전달할 수도 있지만 받아올 수도 있다.
때문에 T&는 입출력 매개변수가 될 수 있다. 이로 인해 문제가 되거나 오류의 원인이 되기도 한다:
void f(string& s)
{
s = "New York"; // non-obvious error
}
void g()
{
string buffer = ".................................";
f(buffer);
// ...
}
여기서, g() 작성자는 f()에게 버퍼를 제공하고 있지만, f()는 참조를 변경해버린다 (이는 문자들을 단순히 복사하는 것보다 비용이 좀 더 발생한다).
g()에서 buffer의 크기를 잘못 가정한다면 오류가 발생할 수 있다.
Enforcement
- (중간) (기본 사항) 함수 내에서 값을 변경하지 않는 비
const참조를 경고한다 - (쉬움) (기본 사항)
const참조 매개변수가move되면 경고한다
F.18: "넘겨주는(will-move-from)" 매개변수는 X&&타입과 std::move로 전달하라
Reason
효율적이고 호출하는 지점에서 버그를 없앤다: X&&는 r-value에 연결되며(bind), l-value를 전달하는 경우 명시적으로 std::move를 호출해야 한다.
Example
void sink(vector<int>&& v) { // sink takes ownership of whatever the argument owned
// usually there might be const accesses of v here
store_somewhere(std::move(v));
// usually no more use of v here; it is moved-from
}
store_somewhere()를 호출할 때 std::move(v)를 사용한 결과 v가 값을 넘겨준(moved-from) 상태로 만든다는 점에 주의하라.
이는 위험할 수도 있다.
Exception
unique_ptr와 같은 유일한 소유자 타입들은 이동만 가능(move-only)하며 쉽게 이동된다(cheap-to-move). 이 타입들은 쉽게 값 전달(pass by value) 코드를 작성하고 수행할 수 있다. 값 전달은 이동 연산이 한번 더 발생하지만, 분명함과 단순함을 우선하라.
예를 들어:
template <class T>
void sink(std::unique_ptr<T> p) {
// use p ... possibly std::move(p) onward somewhere else
} // p gets destroyed
Enforcement
- 모든
std::move없이X&&매개변수를 사용하면 지적한다 (이때X는 템플릿 인자가 아니다) - 값을 넘겨준(moved-from) 개체에 접근하면 지적한다
- 조건부로 개체를 이동시키지 말아라
F.19: "전달(forward)" 매개변수는 TP&&타입과 std::forward로만 전달하라
Reason
만약 개체가 해당 함수에서 바로 사용되지 않고 다른 코드로 전달된다면, 그 함수는 전달인자가 상수(const)인 경우이거나 r-value인 경우에도 동작하도록 작성되어야 한다.
TP가 템플릿형 매개변수면 TP&&는 포워딩 참조가 된다 -- 이 때 상수 속성과 rvalue 속성은 무시 되기도하고 보존 되기도 한다. 그래서 T&&를 사용하는 코드는 변수의 상수 속성과 rvalue 속성에 게의치 않는다는 의미를 내포하지만 (어차피 무시되기 때문에), 값을 전달하는 코드에서는 상수 속성과 rvalue 속성을 신경쓴다 (보존이 되기 때문에). TP&&형 매개변수에 임시객체가 전달되면 함수가 실행되는 동안에는 유효하기 때문에 안전하다. TP&&형 매개변수는 항상 std::forward를 이용하여 함수의 몸체에서 전달되어야 한다.
Example
template <class F, class... Args>
inline auto invoke(F f, Args&&... args) {
return f(forward<Args>(args)...);
}
??? calls ???
Enforcement
- 모든 정적 경로에 대해 단 한번
std::forward하는 경우를 제외하고TP&&매개변수를 받는 함수를 지적한다 (TP는 템플릿 인자의 이름이다).
F.20: "출력(out)"에는 매개변수보다는 값을 반환하는 방법을 선호하라
Reason
매개변수 타입으로 &는 입/출력 혹은 출력으로만 쓰일 수 있는 반면, 반환 값은 잘못 사용되기 어려우며 함수의 결과라는 점을 명확히 한다.
이는 성능 향상과 메모리 관리를 피하기 위해 암묵적으로 이동 연산을 사용하는 표준 컨테이너들 같은 큰 개체에도 적용된다.
만약 다수의 값을 반환해야 한다면, tuple이나 멤버를 가진 타입을 사용하라.
Example
// OK: return pointers to elements with the value x
vector<const int*> find_all(const vector<int>&, int x);
// Bad: place pointers to elements with value x in-out
void find_all(const vector<int>&, vector<const int*>& out, int x);
Note
(각각의 이동 비용이 크지 않은) 멤버를 많이 가진 struct는 전체적으로는 이동 비용이 클 수 있다.
const 값을 반환하는 것은 추천하지 않는다. 오래된 조언들은 무의미하다: 의미도 없고 이동 의미구조를 방해한다.
const vector<int> fct(); // bad: that "const" is more trouble than it is worth
vector<int> g(const vector<int>& vx)
{
// ...
fct() = vx; // prevented by the "const"
// ...
return fct(); // expensive copy: move semantics suppressed by the "const"
}
반환 값에 const를 사용하는 것은 임시 변수에 대한 (굉장히 드문) 우발적 접근을 막기 위한 것이다.
전달 인자에 const가 사용되면 (매우 자주 발생하는) 이동 의미구조를 막는다.
Exceptions
- 상속 계층구조에 속한 타입처럼 값 타입이 아닌 경우, 개체를
unique_ptr혹은shared_ptr로 반환하라 - 많약 값의 이동 비용이 크다면 (
array<BigPOD>같은 경우), 자유 저장소에 할당하고 그 핸들을 (unique_ptr와 같은) 반환하는 것을 고려하라. 또는const가 아닌 참조(출력 매개변수)를 전달해 개체를 채워넣도록 하라 - 최대 크기(capacity)를 가진 개체(예를 들어
std::string,std::vector)를 여러 함수 호출과정에서 재사용하고자 한다면, 입출력 매개변수로 참조를 전달하라.
Example
struct Package { // exceptional case: expensive-to-move object
char header[16];
char load[2024 - 16];
};
Package fill(); // Bad: large return value
void fill(Package&); // OK
int val(); // OK
void val(int&); // Bad: Is val reading its argument
Enforcement
- 큰 비용 없이 반환할 수 있으면서 값을 변경하기 전에 사용하는 비
const참조 매개변수를 지적하라; 이들은 "출력" 반환 값이 적절하다. const반환 값을 지적한다.const를 제거하도록 권한다
F.21: "출력"값 여러 개를 반환할 때는 튜플이나 구조체를 선호하라
Reason
반환 값은 그 자체로 문서가 필요하지 않고 "출력 전용"으로 사용된다.
C++ 에서는 다수의 값을 반환할때는 tuple(pair를 포함해)를 쓴다는 것을 기억하라, 호출한 지점에서 tie를 사용해 받을 것이다.
반환 값에 의미구조가 있다면 별도의 struct 타입을 사용하라. 그렇지 않다면 일반적인 코드에서는 (이름 없는) tuple이 유용하다.
Example
// BAD: output-only parameter documented in a comment
int f(const string& input, /*output only*/ string& output_data)
{
// ...
output_data = something();
return status;
}
// GOOD: self-documenting
tuple<int, string> f(const string& input)
{
// ...
return make_tuple(status, something());
}
사실, C++98의 표준 라이브러리에서는 pair가 개체 2개를 묶은 tuple과 같기 때문에 이 기능을 편리하게 사용하고 있었다.
예를 들어, set<string> my_set이 주어졌다고 가정하면:
// C++98
result = my_set.insert("Hello");
if (result.second) do_something_with(result.first); // workaround
C++11에서는 이렇게 작성할 수 있다, 결과값들을 이미 존재하는 지역변수에 대입한다:
Sometype iter; // default initialize if we haven't already
Someothertype success; // used these variables for some other purpose
tie(iter, success) = my_set.insert("Hello"); // normal return value
if (success) do_something_with(iter);
C++ 17에서는 다수의 변수들을 선언과 동시에 초기화 할 수 있는 "structured bindings"을 지원한다:
if (auto [ iter, success ] = my_set.insert("Hello"); success) do_something_with(iter);
Exception
때에 따라서는 개체의 상태를 변경하기 위해 함수에 개체를 전달해야 할 수도 있다.
그런 경우, 개체를 T& 참조로 전달하는 것이 많은 경우 올바른 방법이다.
반환 값으로 입출력 매개변수를 전달하는 것은 종종 불필요하다.
예를 들어:
istream& operator>>(istream& is, string& s); // much like std::operator>>()
for (string s; cin >> s; ) {
// do something with line
}
여기서 s와 cin 모두 입출력 매개변수로 사용되었다.
cin은 참조로 전달되어 상태를 변경할 수 있다. s는 반복적으로 개체를 할당하는 것을 막으려고 전달한다.
참조로 전달된 s를 재사용하는 것으로, s의 최대 크기(capacity)를 넘어서는 경우에만 새로운 메모리 할당이 발생한다.
이런 방법은 보통 "호출자가 미리 할당해서 출력을 받는" 패턴이라고 불리는데, string이나 vector 같은 메모리 해제가 발생하는 타입들에 유용하다.
비교를 위해, 값을 반환하는 방법으로 해결한다면 아래와 같이 작성하게 될 것이다:
pair<istream&, string> get_string(istream& is); // not recommended
{
string s;
is >> s;
return {is, s};
}
for (auto p = get_string(cin); p.first; ) {
// do something with p.second
}
생각보다 아름답지 않고 성능에도 좋지 않다.
이는 사실 입출력 매개변수에 의존하기 때문에 엄밀하게는 규칙(F.21)에서 말하는 출력 매개변수의 예외가 아니다. 하지만, 가이드라인이 말하지 않아서 놓치는 것보다는 명시적으로 언급하는 것이 분명하기 때문에 작성되었다.
Note
특정한 사용자 정의 타입을 반환하는 것이 유용한 경우도 많이 있다. 예를 들자면:
struct Distance {
int value;
int unit = 1; // 1 means meters
};
Distance d1 = measure(obj1); // access d1.value and d1.unit
auto d2 = measure(obj2); // access d2.value and d2.unit
auto [value, unit] = measure(obj3); // access value and unit; somewhat redundant
// to people who know measure()
auto [x, y] = measure(obj4); // don't; it's likely to be confusing
추상화가 아닌 독립적인 존재들(independent entities)을 표현할 때는 pair와 tuple은 필요 이상으로 범용적(overly-generic)일 수 있다.
다른 예로는, tuple대신 특정 타입과 비슷한 variant<T, error_code>를 사용하라.
Enforcement
- 출력 목적의 매개변수는 반환값으로 대체되어야 한다. 출력 매개변수는 함수(멤버함수 포함)에서 값을 변경하는
const가 아닌 매개변수를 의미한다.
F.22: T* 혹은 owner를 단일 개체를 지정하기 위해 사용하라
Reason
가독성: 일반적인 포인터와 같다. 분석도구의 동작을 돕는다.
Note
전통적인 C와 C++ 코드에서는 T*는 서로 연관이 없는 목적들( weakly-related purposes)에 쓰여왔다:
- (단일) 개체의 확인(identify) (함수에 의해 소멸되지 않았다는 의미)
- 자유 저장소에 할당된 개체의 주소(나중에 해제한다)
nullptr를 담기 위한 용도- (0으로 끝나는 문자 배열) 전통적인 C 언어 문자열
- 길이와 함께 전달되는 배열의 시작 지점
- 배열 내의 위치를 표시
이로 인해 코드가 어떤일을 하는지 이해하기 어려웠고, 도구에 의한 분석을 복잡하게 만들었다.
Example
void use(int* p, int n, char* s, int* q)
{
p[n - 1] = 666; // Bad: we don't know if p points to n elements;
// assume it does not or use span<int>
cout << s; // Bad: we don't know if that s points to a zero-terminated array of char;
// assume it does not or use zstring
delete q; // Bad: we don't know if *q is allocated on the free store;
// assume it does not or use owner
}
아래 코드가 더 낫다
void use2(span<int> p, zstring s, owner<int*> q)
{
p[p.size() - 1] = 666; // OK, a range error can be caught
cout << s; // OK
delete q; // OK
}
Note
owner<T*>는 소유권을 표현한다. zstring은 C 언어 문자열을 의미한다.
T*가 unique_ptr<T>와 같은 스마트 포인터에서 획득되었다면 단일 개체를 의미한다.
See also
Enforcement
- (쉬움) (범위 관련) 포인터 값을 반환하는 산술 연산에 대해 경고한다
F.23: "null"이 허용되지 않는다면 not_null<T>를 사용해 표시하라
Reason
명확성. 함수 호출자가 nullptr 검사를 해야 하는지를 명확히 한다.
같은 맥락으로, not_null<T>을 반환한다면 함수 호출자는 반환 값이 nullptr인지 검사해야 할 필요가 없다.
Example
not_null<T*>은 코드를 읽는 대상(기계와 사람 모두)이 nullptr를 검사할 필요가 없다는 것을 분명히한다. 추가적으로, 디버깅할 때, owner<T*>와 not_null<T>에서 정확성을 검사하는데 사용될 수 있다.
다음의 사례를 고려해 보자:
int length(Record* p);
length(p)을 호출하기 전에 p가 nullptr인지 검사해야 하는가? length()의 구현에서 p가 nullptr인지 검사해야 하는가?
// it is the caller's job to make sure p != nullptr
int length(not_null<Record*> p);
// the implementor of length() must assume that p == nullptr is possible
int length(Record* p);
Note
not_null<T*>는 nullptr가 아니라고 전제한다; T*는 nullptr일 수 있다; 둘 모두 T*로 표현되므로 실행시간 오버헤드가 발생하지 않는다.
Note
not_null는 내장 포인터 타입 뿐만 아니라, unique_ptr, shared_ptr, 혹은 다른 포인터처럼 동작하는 타입들에도 동작한다
Enforcement
- (단순) 원시 포인터(raw pointer)를
nullptr인지 검사하지 않고 사용하면 경고한다not_null를 쓰도록 제안한다 - (단순) 포인터가 역참조 될 때
nullptr를 검사할 때도 있고 검사하지 않을 때도 있다면 오류로 처리한다 - (단순)
not_null이nullptr인지 검사하는 경우 경고한다
F.24: 범위를 지정할 때는 span<T>혹은 span_p<T>를 사용하라
Reason
명시적이지 않은 범위는 오류의 원인이 된다.
Example
X* find(span<X> r, const X& v); // find v in r
vector<X> vec;
// ...
auto p = find({vec.begin(), vec.end()}, X{}); // find X{} in vec
Note
C++ 코드에서 범위를 사용하는 경우는 무척 흔하다. 보통 그런 범위들은 암묵적이고 정확한 사용을 확신하기 매우 어렵다.
특히, 배열 [p:p+n)를 대상으로한 (p, n) 전달인자가 주어졌을 때, 실제로 *p 뒤에 n개의 원소가 실재하는지 아는 것은 불가능하다.
span<T>와 span_p<T>는 [p:q)를 대상으로 앞서 언급한 명제가 사실임을 확인할 수 있도록 하는 단순한 보조(helper) 클래스이다.
Example
span은 원소들의 범위를 표현한다. 그런데 그 범위의 원소들을 어떻게 변경할 수 있을까?
void f(span<int> s)
{
// range traversal (guaranteed correct)
for (int x : s) cout << x << '\n';
// C-style traversal (potentially checked)
for (gsl::index i = 0; i < s.size(); ++i)
cout << s[i] << '\n';
// random access (potentially checked)
s[7] = 9;
// extract pointers (potentially checked)
std::sort(&s[0], &s[s.size() / 2]);
}
Note
span<T>개체는 원소를 소유하지 않며 값에 의한 전달이 가능할 정도로 작다.
span을 인자로 전달하는 것은 포인터와 길이를 함께 전달하는 것보다 효율적이다.
See also
Enforcement
(복잡함) 포인터와 정수를 사용해 범위가 매개변수로 전달되면 경고하고 span을 사용하도록 제안한다.
F.25: C 스타일 문자열에는 zstring 혹은 not_null<zstring>을 사용하라
Reason
C언어 형식의 문자열은 광범위하게 사용되고 있다. 관례적으로, 이들은 \0으로 끝나는 char배열이라고 정의되어 있다.
C 문자열은 char 1개에 대한 포인터와 구분되어야 한다.
Example
Consider:
int length(const char* p);
length(s)를 호출 할 때 s==nullptr을 검사해야 하는가? length() 본문 안에서 p가 nullptr인지 검사해야 하는가?
// the implementor of length() must assume that p == nullptr is possible
int length(zstring p);
// it is the caller's job to make sure p != nullptr
int length(not_null<zstring> p);
Note
zstring은 소유권을 표현하지 않는다.
See also
F.26: 포인터가 필요한 곳에 소유권을 전달할 때는 unique_ptr<T>를 사용하라
Reason
unique_ptr는 포인터를 안전하고 부담없이(cheap) 전달하는 가장 간단한 방법이다.
See also
C.50는 팩토리 함수에서 shared_ptr를 반환하는 경우를 다룬다
Example
unique_ptr<Shape> get_shape(istream& is) // assemble shape from input stream
{
auto kind = read_header(is); // read header and identify the next shape on input
switch (kind) {
case kCircle:
return make_unique<Circle>(is);
case kTriangle:
return make_unique<Triangle>(is);
// ...
}
}
Note
클래스 계층구조에 있는 개체라면 개체 그 자체보다는 인터페이스(상위 클래스)의 포인터를 전달해야 한다.
Enforcement
(단순) 함수가 유효범위 내에서 할당한 포인터를 반환한다면 경고하라. unique_ptr 혹은 shared_ptr를 쓰도록 제안하라
F.27: 소유권을 공유할 때는 shared_ptr<T>를 사용하라
Reason
std::shared_ptr로 소유권을 공유하는 것은 표준에서 사용하는 방법이다. 이를 사용하면, 마지막 소유자가 개체를 소멸시킨다.
Example
shared_ptr<const Image> im { read_image(somewhere) };
std::thread t0 {shade, args0, top_left, im};
std::thread t1 {shade, args1, top_right, im};
std::thread t2 {shade, args2, bottom_left, im};
std::thread t3 {shade, args3, bottom_right, im};
// detach threads
// last thread to finish deletes the image
Note
소유자가 하나 뿐이라면 shared_ptr보다는 unique_ptr을 사용하라.
shared_ptr는 소유권의 공유를 위한 것이다.
shared_ptr가 곳곳에서 사용되면 비용이 발생한다는 점에 주의하라(참조 카운트에 대한 원자적 연산 비용의 총합).
Alternative
특정 범위에서만 사용되는 개체 하나가 공유 개체를 소유하도록 하라. 모든 사용자가 사라졌을때(completed) 공유 개체를 파괴하도록 한다.
Enforcement
(실행 불가) 제대로 탐지하기엔 너무 복잡한 패턴을 띄고 있다.
F.60: "인자가 없을 경우"를 허용한다면 T&보다는 T*를 선호하라
Reason
포인터(T*)는 nullptr일 수 있지만, 참조(T&)는 그렇지 않다.
경우에 따라서는 "개체 없음"을 표시하기 위해 nullptr를 사용하는 것이 유용할 수 있다. 그렇지 않다면, 참조가 더 간단하고 좋은 코드로 이어질 것이다.
Example
string zstring_to_string(zstring p) // zstring is a char*; that is a C-style string
{
if (!p) return string{}; // p might be nullptr; remember to check
return string{p};
}
void print(const vector<int>& r)
{
// r refers to a vector<int>; no check needed
}
Note
가능하기는 하지만, C++에서 nullptr인 개체를 생성하는 것은 정상적(valid)이지 않다(예를 들어, T* p = nullptr; T& r = (T&)*p;). 그런 오류는 굉장히 드물다(very uncommon).
Note
포인터 표기법을 선호한다면 (.보다는 -> 혹은 *가 좋다면), not_null<T*>이 T&처럼 사용될 수 있다.
Enforcement
???
F.42: 위치를 나타내는 경우에만 T*를 반환하라
Reason
포인터는 이를 표현하기에 적절하다.
소유권을 전달하기 위해 T*를 사용하는 것은 잘못된 방법이다.
Example
Node* find(Node* t, const string& s) // find s in a binary tree of Nodes
{
if (!t || t->name == s) return t;
if ((auto p = find(t->left, s))) return p;
if ((auto p = find(t->right, s))) return p;
return nullptr;
}
nullptr가 아니라면 find가 반환하는 포인터는 s를 가지는 node를 의미한다.
중요한점은 개체를 가리키는 포인터로는 소유권이 호출자까지 전달되지 않는다는 것이다.
Note
위치는 반복자, 색인(indices), 참조를 사용해 전달할 수 있다.
종종 참조가 포인터보다 우월한 방법이 되기도 한다. nullptr를 사용할 필요가 없는 경우 혹은 개체가 변경되어선 안되는 경우.
Note
Do not return a pointer to something that is not in the caller's scope; see F.43.
See also
허상 포인터 예방에 대한 토의 (링크 없음)
Enforcement
- 단순한(plain)
T*에delete,free()등이 사용되면 지적한다. 소유권이 있을때만 delete되어야 한다. - 단순한(plain)
T*에new,malloc()등이 사용되면 지적한다. 소유권이 있을때만 delete의 책임이 발생한다.
F.43: 절대로 (직접적이든 간접적이든) 지역 개체의 포인터나 참조를 반환하지 말아라
Reason
허상 포인터(dangling pointer)로 인한 크래시와 데이터 손상(corruption)을 방지한다.
Example, bad
함수가 반환하면 지역 개체들은 더이상 존재하지 않는다:
int* f()
{
int fx = 9;
return &fx; // BAD
}
void g(int* p) // looks innocent enough
{
int gx;
cout << "*p == " << *p << '\n';
*p = 999;
cout << "gx == " << gx << '\n';
}
void h()
{
int* p = f();
int z = *p; // read from abandoned stack frame (bad)
g(p); // pass pointer to abandoned stack frame to function (bad)
}
위와 같은 코드에서 아래와 같은 출력을 확인할 수 있다:
*p == 999
gx == 999
이는 g()에서 f()에서 사용한 스택 영역을 재사용했기 때문인 것으로 생각된다. *p에서 gx가 점유한 메모리 영역을 참조한 것이다.
fx와gx가 다른 타입인 경우를 상상해보라fx와gx에 불변조건이 있는 경우를 상상해보라- 저런 허상 포인터가 더 많은 함수들에서 사용되었을 경우를 상상해보라
- 악의적인 사용자(cracker)가 허상 포인터로 무엇을 할 수 있을지 상상해보라
다행스럽게도 대부분 (모든?) 최신(modern) 컴파일러들은 이런 단순한 오류를 잡아내고 경고할 수 있다.
Note
이 규칙은 참조에도 해당한다:
int& f()
{
int x = 7;
// ...
return x; // Bad: returns reference to object that is about to be destroyed
}
Note
static이 아닌 지역 변수에만 적용된다. 모든 static변수는 (이름에서 드러나듯이) 정적으로 할당되므로, 그 개체를 가리키는 포인터는 허상 포인터가 아니다.
Example, bad
지역 변수에 대한 포인터가 새어나오는 경우가 예시처럼 분명하지 않을 수 있다:
int* glob; // global variables are bad in so many ways
template<class T>
void steal(T x)
{
glob = x(); // BAD
}
void f()
{
int i = 99;
steal([&] { return &i; });
}
int main()
{
f();
cout << *glob << '\n';
}
이 코드에서는 f의 호출 이후 버려진 메모리 영역에서 값을 읽어온다. glob에 저장된 포인터는 예상치 못한 방법으로 멀리(later) 있는 코드에서 사용되면서 문제를 일으킬 수 있다.
Note
지역변수의 주소는 return 구문이나 T& 출력 매개변수를 통해서 반환되거나, 반환 개체의 멤버, 배열과 같은 형태로 새어나올 수 있다.
Note
유사하게 안쪽 유효범위에서 바깥 유효범위로 새어나오는 포인터의 예시들을 더 작성할 수도 있다; 그런 경우들은 함수로부터 새어나온 포인터를 처리하는 방법을 그대로 적용할 수 있다.
이 문제의 파생으로는 컨테이너 안에 포인터를 보관하면서 개체보다 포인터가 더 오래 사용되는(outlives) 경우가 있다.
See also
허상 포인터에 대한 다른 방법으로는 포인터 무효화(링크 없음)를 생각할 수 있다. 이 역시 비슷한 방법으로 탐지되고 예방할 수 있다.
Enforcement
- 컴파일러가 지역변수들에 대한 참조 혹은 포인터를 반환하는 것을 잡아낼 수 있다
- 정적 분석에서 많은 일반적인 패턴을 잡아낼 수 있다 (그러므로 허상 포인터를 제거할 수 있다)
F.44: 복사를 권장하지 않거나 "개체를 항상 반환"한다면 T&를 반환하라
Reason
언어가 T&는 객체를 가리키고 있다는 것을 보장하기 때문에 nullptr인지 시험하는 것은 필요없다.
See also
참조를 반환하는 것은 소유권 이전으로 사용되어선 안된다: 허상 포인터 예방에 대한 토의(discussion) and 소유권에 대한 토의(discussion).
Example
class Car
{
array<wheel, 4> w;
// ...
public:
wheel& get_wheel(int i) { Expects(i < w.size()); return w[i]; }
// ...
};
void use()
{
Car c;
wheel& w0 = c.get_wheel(0); // w0 has the same lifetime as c
}
Enforcement
반환이 없는 경우 nullptr가 될 수 있는 함수들을 지적한다
F.45: T&&를 반환하지 말아라
Reason
이것은 소멸된 임시 개체에 대한 참조를 반환하는 것이다. &&는 임시 개체를 붙잡기 위한 것이다.
Example
r-value 참조는 반환한 표현식이 끝나면 유효범위에서 사라진다:
auto&& x = max(0, 1); // OK, so far
foo(x); // Undefined behavior
이런 종류의 사용은 버그의 원인이되고, 컴파일러 버그라고 잘못 보고된다. 함수를 구현할때 사용자가 이런 함정에 빠지지 않도록 해야 한다.
수명주기 안전성 분석(profile)에서 이런 문제를 잡아낼 것이다(완전히 구현된다면).
Example
r-value 참조를 반환하는 것은 해당 임시변수에 대한 참조가 피호출자로 "하향식 전달" 되된다면 문제없다; 그런 경우, 그 임시변수는 함수 호출보다 오래 지속될 수 있다(F.18와 F.19를 함께 보라). 하지만, 호출자로 참조가 "상향식 전달"된다면 문제가 될 수 있다.
(보통의 참조 혹은 perfect forwarding을 통해서) 함수 인자를 연속 전달(passthrough)하고자 한다면, (auto&&가 아니라) auto를 사용하라
F가 값으로 반환한다고 가정하면:
template<class F>
auto&& wrapper(F f)
{
log_call(typeid(f)); // or whatever instrumentation
return f(); // BAD: 임시변수에 대한 참조를 반환한다
}
이런 코드가 더 낫다:
template<class F>
auto wrapper(F f)
{
log_call(typeid(f)); // or whatever instrumentation
return f(); // OK
}
Exception
std::move 와 std::forward는 &&를 반환하지만 이는 형변환일 뿐이다 -- 표현식 문맥내에서 임시 개체가 파괴되기 전에 같은 표현식 내에서 임시 개체에 대한 참조를 전달한다.
우리는 &&를 반환하는 것의 다른 좋은 형태를 알지 못한다.
Enforcement
std::move 와 std::forward를 제외하고 &&를 반환한다면 지적한다
F.46: main()는 int를 반환해야 한다
Reason
언어 규칙으로 정해져 있지만. "언어 확장"에 의해서 너무 자주 위반된다.
main(해당 프로그램의 main 함수)에서 void를 반환하도록 선언하는 것은 이식성을 제한한다.
Example
void main() { /* ... */ }; // bad, not C++
int main()
{
std::cout << "This is the way to do it\n";
}
Note
커뮤니티에 이 문제가 남아있기 때문에 가이드라인에서 명시한다.
Enforcement
- 컴파일러에서 금지한다
- 컴파일러가 금지하지 않는다면 분석 도구에서 이를 지적한다
F.47: 대입 연산자는 T&를 반환하라
Reason
값 타입의 연산자 중복정의는 전통적으로 대입에 operator=(const T&)를 사용하고 *this를 (const가 아닌 형태로) 반환하는 것이다.
이렇게 하는 것이 표준 라이브러리 타입들과 일관성을 유지하고 "int처럼 동작하는" 원칙을 따르는 것이다.
Note
과거에는 대입 연산에서 const T&를 반환하도록 하는 가이드가 있었다.
이는 (a = b) = c같은 형태의 코드를 예방하기 위한 목적이었다 -- 이런 코드는 표준 타입들과의 일관성을 해칠 정도로 빈번하지는 않다.
Example
class Foo
{
public:
...
Foo& operator=(const Foo& rhs) {
// Copy members.
...
return *this;
}
};
Enforcement
이 규칙은 반환 타입(과 반환 값)을 검사하는 도구에 의해서 모든 대입 연산자에 대해 적용되어야 한다.
F.48: return std::move(local)은 사용하지 말아라
Reason
Guaranteed copy elision이 적용되면 std::move를 반환 구문에 사용할 필요가 없다.
Example; bad
S f()
{
S result;
return std::move(result);
}
Example; good
S f()
{
S result;
return result;
}
Enforcement
반환 구문을 검사하는 도구에 의해서 검사되어야 한다.
F.50: 함수를 쓸 수 없을 때는 람다를 사용하라(지역 변수를 캡쳐하거나 지역 함수를 작성할 때)
Reason
함수는 지역변수를 캡쳐할 수 없고, 지역 유효범위로 선언될 수도 없다; 이런 기능이 필요하다면 람다를 사용하거나 직접 작성한 함수 개체를 사용해야 한다 (가능한 람다를 사용하라). 하지만, 람다와 함수개체는 오버로드가 되지 않는다; 오버로드가 필요하다면 함수를 사용하라. 두 방법 모두 가능하다면 함수를 선호하라; 단순한 방법을 사용하라.
Example
// writing a function that should only take an int or a string
// -- overloading is natural
void f(int);
void f(const string&);
// writing a function object that needs to capture local state and appear
// at statement or expression scope -- a lambda is natural
vector<work> v = lots_of_work();
for (int tasknum = 0; tasknum < max; ++tasknum) {
pool.run([=, &v]{
/*
...
... process 1 / max - th of v, the tasknum - th chunk
...
*/
});
}
pool.join();
Exception
제네릭 람다는 함수 템플릿을 구현하는 간결한 방법을 제공하기 때문에 코드를 조금 더 작성하면 일반 함수 템플릿과 같은 기능을 사용할 수 있다. 미래에 모든 함수들이 Concept 인자를 사용할 수 있게 되면 이 기능은 사라질지도 모른다.
Enforcement
- 아무것도 캡쳐하지 않는 비-제네릭 람다가 전역 범위에 나타나면 경고한다(예를 들어,
auto x = [](int i){ /*...*/; };와 같은 형태). 이런 경우 람다 대신 평범한 함수를 작성하도록 한다.
F.51: 선택할 수 있다면, 중복 정의보다는 기본 전달인자를 선호하라
Reason
기본 인자로 하나의 구현에 다른 인터페이스를 제공할 수 있다. 모든 중복 정의가 같은 의미구조를 구현한다고 보장할 수 없다. 기본인자를 사용함으로써 코드 중복을 피할 수 있다.
Note
전달인자가 같은 타입일 때는 기본인자와 중복정의 중에서 선택해야 할 때가 있다:
void print(const string& s, format f = {});
그 반대로는
void print(const string& s); // use default format
void print(const string& s, format f);
의미구조적으로는 같은 연산이지만 전달인자의 타입이 다르다면 선택의 여지가 없다. 예를 들어:
void print(const char&);
void print(int);
void print(zstring);
See also
Enforcement
???
F.52: 지역적으로 사용된다면 람다의 참조 캡쳐를 선호하라
Reason
지역범위에서 람다를 사용할 때는 대부분의 경우 효율성과 정확성을 위해 참조캡쳐(capture by reference)를 선호할 것이다. 여기에는 함수가 반환하기 전에 병렬 알고리즘을 작성하거나 호출할때도 포함된다.
Discussion
효율적인 측면에서는 대부분의 타입들을 참조로 전달하는 것이 값으로 전달하는 것보다 효율적이다.
정확성 측면에서는 연산들이 호출 지점에서 원래 개체에 부수효과를 만들길 원한다는 것을 고려해야 한다. 값으로 전달하면 이런 문제를 예방할 수 있다.
Note
불행하게도, 부수효과를 막기 위해 참조를 const로 받아올 방법이 없다
Example
이 예시에서는, 큰 개체(네트워크 메세지)가 반복 알고리즘에 전달된다. 이 개체가 복사 가능하더라도 복사하는 것은 효율적이지도, 정확하지도 않다:
std::for_each(begin(sockets), end(sockets), [&message](auto& socket)
{
socket.send(message);
});
Example
아래 예제는 간단한 3단계 병렬 파이프라인이다.
각 stage 개체는 process 함수를 통해 작업을 전달하고 작업 큐가 소진될 때까지 소멸되지 않는 작업용 스레드들을 캡슐화 한 것이다.
void send_packets(buffers& bufs)
{
stage encryptor([] (buffer& b){ encrypt(b); });
stage compressor([&](buffer& b){ compress(b); encryptor.process(b); });
stage decorator([&](buffer& b){ decorate(b); compressor.process(b); });
for (auto& b : bufs) {
decorator.process(b);
}
} // automatically blocks waiting for pipeline to finish
Enforcement
지역적으로 사용되지 않거나 참조로 전달되는데 참조로 캡쳐하는 람다를 지적한다. (주의: 이 규칙은 추정에 의한 것이다. 하지만 포인터로 전달된다면 피호출자에 저장되거나, 매개변수로 접근되거나, 람다에 의해서 반환되는 등으로 사용될 가능성이 높다. 수명주기 규칙들이 유효범위를 벗어나는 포인터나 람다를 통해 참조되는 경우를 지적하기 위한 규칙들을 제공한다.)
F.53: 지역적으로 사용되지 않는다면 참조 캡쳐를 피하라
Reason
지역범위에 있는 포인터와 참조는 범위를 넘어서면 더 이상 존재하지 않는다. 참조캡쳐를 가진 람다는 지역 개체를 참조하고 있을 뿐이며, 지역범위를 넘어서면 더 이상 참조해서는 않된다.
Example, bad
int local = 42;
// Want a reference to local.
// Note, that after program exits this scope,
// local no longer exists, therefore
// process() call will have undefined behavior!
thread_pool.queue_work([&]{ process(local); });
Example, good
int local = 42;
// Want a copy of local.
// Since a copy of local is made, it will
// always be available for the call.
thread_pool.queue_work([=]{ process(local); });
Enforcement
- (단순) 캡쳐 목록이 지역 변수를 참조하면 경고한다
- (복잡) 캡쳐 목록이 지역 변수를 참조하고
const가 아니거나 비-지역적 문맥으로 전달되면 지적한다
F.54: this를 캡쳐할 때는, 모든 변수를 명시적으로 캡쳐하라(기본 캡쳐를 사용하지 않는다)
Reason
명시하지 않으면 혼란스럽다. 멤버 함수 안에서 [=]를 사용하는 것은 값으로 캡쳐하는 것이지만, 실제로는 보이지 않는 this를 복사하면서 데이터 멤버를 참조하는 방식으로 캡쳐하는 것이다.
이것이 의도된 것이라면, this를 명시적으로 사용해야 한다.
Example
class My_class {
int x = 0;
// ...
void f() {
int i = 0;
// ...
auto lambda = [=]{ use(i, x); }; // BAD: "looks like" copy/value capture
// [&] has identical semantics and copies the this pointer under the current rules
// [=,this] and [&,this] are not much better, and confusing
x = 42;
lambda(); // calls use(0, 42);
x = 43;
lambda(); // calls use(0, 43);
// ...
auto lambda2 = [i, this]{ use(i, x); }; // ok, most explicit and least confusing
// ...
}
};
Note
표준에서 이에 대해 계속 논의중이다. 이후 표준에서 새로운 캡쳐 방식이 도입되거나 [=]의 의미를 수정하는 형태로 조정될 수 있다.
지금은 명시적으로 코드를 작성하라.
Enforcement
- 기본 캡쳐와
this가 캡쳐목록에 포함된 람다들을 지적한다 (명시적이든 기본 캡쳐한 것이든)
F.55: va_arg 전달인자를 사용하지 말아라
Reason
va_arg에서 값을 읽어올 때는 타입이 정확히 전달되었다고 가정한다. va_arg에 값을 전달할때는 타입이 정확히 읽힐 것이라고 가정한다.
이는 위태로운 방법인데 언어에 의존하지 않고 프로그래머가 기능을 정확히 사용해야 때문이다.
Example
int sum(...) {
// ...
while (/*...*/)
result += va_arg(list, int); // BAD, assumes it will be passed ints
// ...
}
sum(3, 2); // ok
sum(3.14159, 2.71828); // BAD, undefined
template<class ...Args>
auto sum(Args... args) { // GOOD, and much more flexible
return (... + args); // note: C++17 "fold expression"
}
sum(3, 2); // ok: 5
sum(3.14159, 2.71828); // ok: ~5.85987
Alternatives
- 중복 정의(overloading)
- 가변 템플릿(variadic templates)
variant전달인자(argument)initializer_list(homogeneous)
Note
... 매개변수를 선언하는 것은 실제 전달인자를 포함하지 않거나, 다른 중복 정의를 허용하지 않기 위해 "인자를 무엇이든" 처리하는 함수 혹은 템플릿 메타 프로그램에서 계산 외의 경우를 잡아내는데 유용하게 쓰이기도 한다.
Enforcement
va_list,va_start,va_arg를 사용하면 반대한다(Issue a diagnostic).- 함수의 가변 매개변수로 넘기는 전달인자에 대해 보다 구체적인 중복정의를 제공하지 않는다고 이의를 제기한다(Issue a diagnostic). 수정하려면 다른 함수를 쓰거나
[[suppress(types)]]를 사용하도록 한다.